 单机数据持久-数据完整性和保护
单机数据持久-数据完整性和保护type
status
date
slug
summary
tags
category
icon
password
Property
磁盘故障模式
磁盘并不完美,并且可能会发生故障(有时)。在早期的RAID 系统中,故障模型非常简单:要么整个磁盘都在工作,要么完全失败,而且检测到这种故障很简单。这种磁盘故障的故障—停止(fail-stop)模型使构建RAID 相对简单。
而现代磁盘似乎大部分时间正常工作,但是无法成功访问一个或几个块。具体来说,两种类型的单块故障是常见的,值得考虑:潜在扇区错误(Latent-SectorErrors,LSE)和块讹误。
- 潜在扇区错误(Latent-Sector Errors,LSE)
如果磁头由于某种原因接触到表面(磁头碰撞,head crash,在正常操作期间不应发生的情况),则可能会
讹误表面,使得数据位不可读。宇宙射线也会导致数据位翻转,使内容不正确。幸运的是,驱动器使用磁盘内纠错码(Error Correcting Code,ECC)来确定块中的磁盘位是否良好,并且在某些情况下,修复它们。如果它们不好,并且驱动器没有足够的信息来修复错误,则在发出请求读取它们时,磁盘会返回错误。- 块讹误(block corruption)
磁盘块出现讹误,但磁盘本身无法检测到。例如,有缺陷的磁盘固件可能会将块写入错误的位置。在这种情况下,磁盘 ECC 指示块内容很好,但是从客户端的角度来看,在随后访问时返回错误的块。类似地,当一个块通过有故障的总线从主机传输到磁盘时,它可能会讹误。由此产生的讹误数据会存入磁盘,但它不是客户所希望的。这些类型的故障特别隐蔽,因为它们是无声的故障(silent fault)。返回故障数据时,磁盘没有报告问题。

该表显示了在研究过程中至少出现一次 LSE 或块讹误的驱动器百分比(大约 3 年,超过 150 万个磁盘驱动器)。该表进一步将结果细分为“廉价”驱动器(通常为 SATA驱动器) 和“昂贵”驱动器(通常为 SCSI 或 FibreChannel)。
关于 LSE 的一些其他发现如下:
- 具有多个 LSE 的昂贵驱动器可能会像廉价驱动器一样产生附加错误。
- 对于大多数驱动器,第二年的年度错误率会增加。
- LSE 随磁盘大小增加。
- 大多数磁盘的 LSE 少于 50 个。
- 具有 LSE 的磁盘更有可能发生新增的 LSE。
- 存在显著的空间和时间局部性。
- 磁盘清理很有用(大多数 LSE 都是这样找到的)。
关于讹误的一些发现如下:
- 同一驱动器类别中不同驱动器型号的讹误机会差异很大。
- 老化效应因型号而异。
- 工作负载和磁盘大小对讹误几乎没有影响。
- 大多数具有讹误的磁盘只有少数讹误。
- 讹误不是与一个磁盘或 RAID 中的多个磁盘无关的。
- 存在空间局部性和一些时间局部性。
- 与 LSE 的相关性较弱。
处理潜在的扇区错误
潜在的扇区错误很容易处理,因为它们(根据定义)很容易被检测到。当存储系统尝试访问块,并且磁盘返回错误时,存储系统应该就用它具有的任何冗余机制, 来返回正确的数据。例如,在镜像 RAID 中,系统应该访问备用副本。在基于奇偶校验的 RAID-4 或 RAID-5 系统中,系统应通过奇偶校验组中的其他块重建该块。因此,利用标准冗余机制,可以容易地恢复诸如 LSE 这样的容易检测到的问题。
多年来,LSE 的日益增长影响了RAID 设计。当全盘故障和LSE 接连发生时,RAID-4/5系统会出现一个特别有趣的问题。具体来说,当整个磁盘发生故障时,RAID 会尝试读取奇偶校验组中的所有其他磁盘,并重新计算缺失值,来重建(reconstruct)磁盘(例如,在热备用磁盘上)。如果在重建期间,在任何一个其他磁盘上遇到LSE,我们就会遇到问题:重建无法成功完成。
为了解决这个问题,一些系统增加了额外的冗余度。例如,NetApp 的RAID-DP 相当于两个奇偶校验磁盘,而不是一个。在重建期间发现LSE 时,额外的校验盘有助于重建丢失的块。与往常一样,这有成本,因为为每个条带维护两个奇偶校验块的成本更高。但是,NetApp WAFL 文件系统的日志结构特性在许多情况下降低了成本。另外的成本是空间,需要额外的磁盘来存放第二个奇偶校验块。
检测讹误:校验和
如何处理数据讹误导致的无声故障?
现代存储系统用于保持数据完整性的主要机制称为校验和(checksum)。校验和就是一个函数的结果,该函数以一块数据(例如 4KB 块)作为输入,并计算这段数据的函数,产生数据内容的小概要(比如 4 字节或 8 字节)。此摘要称为校验和。这种计算的目的在于,让系统将校验和与数据一起存储,然后在访问时确认数据的当前校验和与原始存储值匹配,从而检测数据是否以某种方式被破坏或改变。
常见的校验和函数
使用基于异或(XOR)的校验和,只需对需要校验和的数据块的每个块进行异或运算,从而生成一个值,表示整个块的 XOR:
True | True | False |
True | False | True |
False | True | True |
False | False | False |
交换律:
结合律:
恒等律:
归零律:
自反:
以每行 4 个字节为一组排列数据,所以很容易看出生成的校验和是什么。只需对每列执行XOR以获得最终的校验和值(有 0 个或 2 个 1 就是 0,有 1 个或 3 个 1 就是 1):
XOR 是一个合理的校验和,但有其局限性。例如,如果每个校验和单元内同一列的两个位发生变化,则校验和将不会检测到讹误
另一个简单的校验和函数是加法。这种方法具有快速的优点。计算它只需要在每个数据块上执行二进制补码加法,忽略溢出。它可以检测到数据中的许多变化,但如果数据被移位,则不好
Fletcher 校验和(Fletcher checksum)
它非常简单,涉及两个校验字节 s1 和 s2 的计算。假设块 D 由字节 d1,…, dn 组成。s1 简单地定义如下:s1 = s1 + di mod 255(在所有 di 上计算)。s2 依次为:s2 = s2 + s1 mod 255(同样在所有 di 上)
fletcher 校验和几乎与 CRC一样强,可以检测所有单比特错误,所有双比特错误和大部分突发错误
循环冗余校验(CRC)
你所做的只是将 D 视为一个大的二进制数(毕竟它只是一串位)并将其除以约定的值(k)。该除法的其余部分是 CRC 的值。
g(x)和 h(x)的除运算,可以通过 g 和 h 做xor(异或)运算。比如将 11001 与 10101 做 xor 运算:
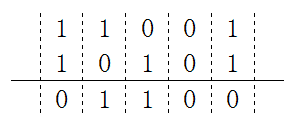
明白了 xor 运算法则后,举一个例子使用
CRC-8算法求 101001110100001 的效验码。CRC-8 标准的 ,既 h 是 9 位的二进制串 111010101。
无论使用何种方法,很明显没有完美的校验和:两个具有不相同内容的数据块可能具有相同的校验和,这被称为碰撞(collision)
校验和布局
最基本的方法就是为
每个磁盘扇区(或块)存储校验和。给定数据块 D,称该数据的校验和为 C(D)。没有校验和,磁盘布局:
有了校验和,布局为每个块添加一个校验和:

因为校验和通常很小(例如,8 字节),并且磁盘只能以扇区大小的块(512 字节)或其倍数写入,所以出现的一个问题是如何实现上述布局。驱动器制造商采用的一种解决方案是使用 520 字节扇区格式化驱动器,每个扇区额外的 8 个字节可用于存储校验和
在没有此类功能的磁盘中,文件系统必须找到一种方法来将打包的校验和存储到 512 字节的块中。一种可能性如下:

在该方案中,n 个校验和一起存储在一个扇区中,后跟n个数据块,接着是后n块的另一个校验和扇区,依此类推。该方案具有在所有磁盘上工作的优点,但效率较低。例如,如果文件系统想要覆盖块D1,它必须读入包含C(D1)的校验和扇区,更新其中的C(D1),然后写出校验和扇区以及新的数据块 D1(因此,一次读取和两次写入)。前面的方法(每个扇区一个校验和)只执行一次写操作。
使用校验和
读取块D 时,客户端(即文件系统或存储控制器)也从磁盘Cs(D)读取其校验和,这称为存储的校验和(storedchecksum,因此有下标Cs)。然后,客户端计算读取的块D 上的校验和,这称为计算的校验和(computed checksum)Cc(D)。此时,客户端比较存储和计算的校验和。如果它们相等 [即Cs(D)== Cc(D)],数据很可能没有被破坏,因此可以安全地返回给用户。如果它们不匹配 [即Cs(D)!= Cc(D)],则表示数据自存储之后已经改变(因为存储的校验和反映了当时数据的值)。在这种情况下,存在讹误,校验和帮助我们检测到了。
发现了讹误,自然的问题是我们应该怎么做呢?如果存储系统有冗余副本,尝试使用它。如果存储系统没有此类副本,则可能的答案是返回错误。在任何一种情况下,都要意识到讹误检测不是神奇的子弹。如果没有其他方法来获取没有讹误的数据,那你就不走运了。
一个新问题:错误的写入
“错误位置的写入(misdirected write)”。这出现在磁盘和RAID控制器中,它们正确地将数据写入磁盘,但位置错误。在单磁盘系统中,这意味着磁盘写入块 Dx 不是在地址 x(像期望那样),而是在地址 y(因此是“讹误的”Dy)。另外,在多磁盘系统中,控制器也可能将 Di,x 不是写入磁盘 i 的 x,而是写入另一磁盘 j。
存储系统或磁盘控制器应该如何检测错误位置的写入?校验和需要哪些附加功能?
答案很简单:在每个校验和中添加更多信息。在这种情况下,添加物理标识符(Physical Identifier,物理 ID)非常有用。例如,如果存储的信息现在包含校验和 C(D) 以及块的磁盘和扇区号,则客户端很容易确定块内是否存在正确的信息。具体来说,如果客户端正在读取磁盘 10 上的块 4(D10,4),则存储的信息应包括该磁盘号和扇区偏移量,如下所示。如果信息不匹配,则发生了错误位置写入,并且现在检测到讹误。以下是在双磁盘系统上添加此信息的示例:

可以从磁盘格式看到,磁盘上现在有相当多的冗余:对于每个块,磁盘编号在每个块中重复,并且相关块的偏移量也保留在块本身旁边。但是,冗余信息的存在应该是不奇怪。冗余是错误检测(在这种情况下)和恢复(在其他情况下)的关键。一些额外的信息虽然
不是完美磁盘所必需的,但可以帮助检测出现问题的情况。
最后一个问题:丢失的写入
丢失的写入(lost write)当设备通知上层写入已完成,但事实上它从未持久,就会发生这种问题。因此,磁盘上留下的是该块的旧内容,而不是更新的新内容
某些系统在系统的其他位置添加校验和,以检测丢失的写入。例如,Sun 的 Zettabyte 文件系统(ZFS)在文件系统的每个 inode 和间接块中,包含文件中每个块的校验和。因此,即使对数据块本身的写入丢失,inode 内的校验和也不会与旧数据匹配。只有当同时丢失对 inode 和数据的写入时,这样的方案才会失败。
擦净
这些校验和何时实际得到检查?当然,在应用程序访问数据时会发生一些检查,但大多数数据很少被访问,因此将保持未检查状态。
许多系统利用各种形式的磁盘擦净(disk scrubbing)。通过定期读取系统的每个块,并检查校验和是否仍然有效,磁盘系统可以减少某个数据项的所有副本都被破坏的可能性。典型的系统每晚或每周安排扫描。
校验和的开销
- 空间开销
空间开销有两种形式。第一种是磁盘(或其他存储介质)本身。每个存储的校验和占用磁盘空间,不能再用于用户数据。典型的比率可能是每4KB 数据块的8 字节校验和,磁盘空间开销为0.19%。
第二种空间开销来自系统的内存。访问数据时,内存中必须有足够的空间用于校验和以及数据本身。但是,如果系统只是检查校验和,然后在完成后将其丢弃,则这种开销是短暂的,并不是很重要。只有将校验和保存在内存中(为了增加内存讹误防护级别),才能观察到这种小开销。
- 时间开销
CPU 必须计算每个块的校验和,包括存储数据时(确定存储的校验和的值),以及访问时(再次计算校验和, 并将其与存储的校验和进行比较)。
除了 CPU 开销之外,一些校验和方案可能会导致外部 I/O 开销,特别是当校验和与数据分开存储时(因此需要额外的 I/O 来访问它们),以及后台擦净所需的所有额外 I/O。